In the previous article we discussed scaling. As we have identified, scaling can improve your availability but its primary goal is resource allocation whereas availability focusses on how and when those resources can be accessed.
When it comes to availability, there are two important pillars:
- Contract (Service Level Agreement) with guarantees and financial consequences;
- Technology responsible for maintaining availability.
Service Level Agreement
When designing your solution with the SLA requirements in mind, you will get a piece of mind when it comes to the availability of your solution. But it comes with a price as well. And do remember, this is not disaster recovery. The SLA usually comes when you deploy multiple instances of your solution in a specific configuration, still focusing on one region. But what if that region becomes unavailable? Then you might need a different disaster recovery scenario to support your needs.
Service Level Agreements: IaaS vs PaaS
As we have pointed out multiple times in this series of articles; there are different levels of service and availability you can expect depending on the platform you are deploying on. The higher up you go on the Azure Platform (IaaS -> PaaS -> SaaS), the more responsibility regarding availability is delegated to Microsoft. In the end you are still ultimately responsible for the availability of your solution, but that starts with choosing the right platform to meet your availability requirements.
For illustration, let’s compare the SLA requirements of Virtual Machines to the requirements of App Services.
Virtual Machines
- For all Virtual Machines that have two or more instances deployed across two or more Availability Zones in the same Azure region, we guarantee you will have Virtual Machine Connectivity to at least one instance at least 99.99% of the time.
- For all Virtual Machines that have two or more instances deployed in the same Availability Set, we guarantee you will have Virtual Machine Connectivity to at least one instance at least 99.95% of the time.
- For any Single Instance Virtual Machine using premium storage for all Operating System Disks and Data Disks, we guarantee you will have Virtual Machine Connectivity of at least 99.9%.
Source: Microsoft March 2018
App Services
We guarantee that Apps running in a customer subscription will be available 99.95% of the time. No SLA is provided for Apps under either the Free or Shared tiers.
Source: Microsoft July 2016
What is clearly pointed out here: the requirements to get a pretty good SLA (99.95%) are much lower for Web Apps as they are for Virtual Machines. In any case where you want to reach that 99.95% with Virtual Machines, you need to configure at least two or more instances in an availability set. Additionally, your application needs to be compatible with load balancing technology as the SLA focuses on two or more virtual machines. To summarize configuring for an SLA for IaaS takes more resources, is probably more expensive and they take more attention from an IT management perspective (updates, configuration adjustments and back-up). Whereas with a regular App Service you already get that SLA with a single deployment.
Technology
Apart from the contractual aspects, your choices of technology will greatly impact the amount of recovery scenario’s that are available to you, regardless of the SLA. If you choose the right configuration you can eventually end up with much more control over your availability as opposed to just going with the SLA requirements.
When building your solution take the following best practices into account:
Deploy from a source control provider
Deploying your solution from a repository, through release management or through any continuous deployment pipeline will guarantee that you always have your application stored somewhere away from your infrastructure (next to all the other benefits this practice will give you). In a scenario where you need to redeploy your solution it is a matter of preparing the infrastructure and push your software once more. Be aware, this is not a recovery scenario for data.
Great solutions are using the Deployment Center for Azure App Services or Azure DevOps to manage your CI/CD. If you’re looking for a different solution, GitHub is also a great way to start!
When using Virtual Machines use Azure Back-Up
If you opt to go for a single instance virtual machine without SLA, make sure to implement Azure Back-up as this will give you a viable recovery scenario. Additionally, you can look into Azure Recovery Services, replicating your environment across regions.
When using storage (For Example Azure SQL, Storage Accounts, Cosmos DB), configure Geo-replication
When using PaaS resources enable Geo Redundancy which usually comes as an optional configuration with the platform. By enabling Geo Redundancy your data will be replicated to another region making sure it is available quickly when a necessary.
For example, when using storage account the following applies:
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9's) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn't recoverable.
Source: Microsoft, October 2018
When using Azure SQL or Cosmos DB, you have much more options at your disposal. You can configure your application with active geo-replication which also allows you build globally distributed applications (see our article on scaling)
Implement Traffic Manager
Traffic Manager is the go-to resource when configuring global availability for your application. It’s easy to configure, supports multiple endpoints and integrates seamlessly with Azure PaaS resources. Traffic Manager will provide you with a single-entry point to your application and based on the routing method you prefer you can route traffic to the corresponding backend. Not only great for globally distributing your application (as traffic manager can route traffic based on the originating DNS request) but also a great way to ensure your customers don’t need to change their URL’s when a region failure occurs.

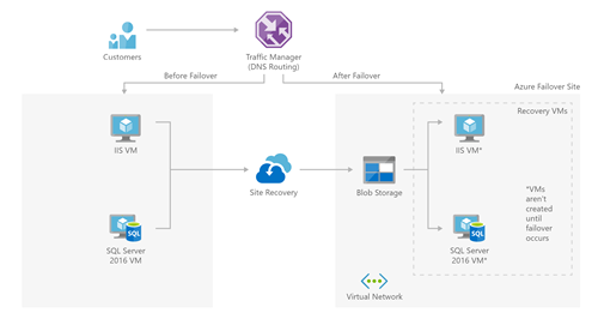
Source: Microsoft
Microsoft has provided several reference architecture regarding disaster recovery which can be found here.
