In het vorige artikel hebben we het gehad over schaalbaarheid. Hier hebben we aangegeven dat dit de beschikbaarheid kan verbeteren. Echter, het voornaamste doel van schaalbaarheid is het toewijzen van resources, terwijl beschikbaarheid zich juist focust op hoe en wanneer je deze resources kan benaderen/gebruiken.
Als het gaat om beschikbaarheid maken we onderscheid tussen twee aandachtsgebieden:
- Contract (Service level Agreement) met financiële garanties en consequenties;
- Technologie welke wordt gebruikt voor het bewerkstelligen van een hogere beschikbaarheid.
Service Level Agreement (SLA)
Tijdens het ontwerpen van jouw oplossing met de SLA-vereisten in gedachten, krijg je een stukje gemoedsrust als het gaat om de beschikbaarheid van jouw oplossing, want je oplossing voldoet aan de SLA eisen. Maar, hier zit wel een prijskaartje aan.. Maar onthoudt wel dat we het hier niet over disaster recovery hebben.
Je oplossing valt doorgaans onder de SLA wanneer je meerdere exemplaren (instances) hebt uitgerold in een specifieke configuratie (bijvoorbeeld availability sets of zones), echter hebben we het hier nog steeds over de uitrol binnen een enkele regio. Wat als die regio niet meer beschikbaar is? Hoewel je een SLA hebt waarin zelfs een financiële vergoeding is vastgelegd, zit je nog steeds met de uitdaging: je applicatie is niet beschikbaar. Wat je uiteindelijk wil, is niet alleen een SLA maar ook een goed doordacht disaster recovery scenario.
Service Level Agreements: IaaS vs PaaS
Zoals we in deze reeks artikelen al vaker hebben aangegeven kent Azure verschillende niveaus van service en beschikbaarheid, afhankelijk van het platform waarop je implementeert. Hoe verder je standaardiseert op native Azure technologie (IaaS -> PaaS -> SaaS), hoe meer verantwoordelijkheid ten aanzien van de beschikbaarheid wordt overgedragen aan Microsoft. Uiteindelijk ben je nog steeds zelf eindverantwoordelijk voor de beschikbaarheid van je oplossing, maar het begint allemaal bij het kiezen van het juiste platform om aan jouw beschikbaarheidsvereisten te voldoen.
Om dit te illustreren, even een kleine vergelijking tussen de SLA-vereisten van Virtuele Machines en WebApps.
Virtual Machines
- Voor alle Virtuele Machines waarbij twee of meer instances zijn geïmplementeerd in twee of meer beschikbaarheidszones binnen dezelfde Azure-regio, garanderen we dat u ten minste 99,99% van de tijd connectiviteit met ten minste één instance van de Virtuele Machine hebt.
- Voor alle Virtuele Machines waarbij twee of meer instances zijn geïmplementeerd binnen dezelfde Availability Set, garanderen we u ten minste 99,95% van de tijd connectiviteit met ten minste een instance van de Virtuele Machine hebt.
- Voor Single-Instance Virtuele Machines die gebruikmaken van premium opslag voor alle Operating System-schijven en Gegevensschijven, garanderen we u ten minste 99,9% van de tijd Connectiviteit van Virtuele Machines hebt.
Bron: Microsoft maart 2018
App Services
We garanderen dat alle Apps die worden uitgevoerd in het kader van het abonnement van een klant ten minste 99,95% van de tijd beschikbaar is. Er wordt geen SLA verstrekt voor Apps die worden uitgevoerd onder de Free- of Shared-laag.
Bron: Microsoft juli 2016
Wat we hier duidelijk kunnen zien is dat de vereisten voor het verkrijgen van een goede SLA (99,95%) veel lager zijn voor Web Apps dan voor Virtual Machines. Als je met een Virtual Machine de 99,95% SLA wilt bereiken moet je ten minste twee of meer instances in een Availability Set configureren. Bovendien moet de applicatie compatibel zijn met load balancing technologie, aangezien de SLA zich richt op twee of meer Virtual Machines.
Samengevat: Maak je gebruik van IaaS dan heb je simpelweg meer resources nodig om je omgeving conform de SLA vereisten te configureren. Dit is waarschijnlijk duurder en heeft meer aandacht nodig vanuit een IT-beheerperspectief (denk aan updates, aanpassingen in configuratie en back-up). Terwijl je met een reguliere App-Service die SLA al met één deployment krijgt en je hoeft de onderliggende infrastructuur niet te beheren.
Technologie
Afgezien van contractuele aspecten is de keuze van technologie van grote invloed op het aantal beschikbare disaster recovery scenario’s, ongeacht de SLA. Als je de juiste (technische) configuratie kiest, heb je uiteindelijk veel meer controle over de beschikbaarheid van je oplossing.
Houd daarom bij het ontwikkelen van je oplossing rekening met de volgende praktische tips:
Deploy vanuit een source control provider
Als je de oplossing uitrolt vanuit een repository, via releasemanagement of via een continuous deployment pipeline, gegarandeert dat jouw applicatie altijd ergens anders dan in de infrastructuur wordt opgeslagen (naast alle andere voordelen die dit je biedt). Wanneer een regio uitvalt en je de oplossing opnieuw moet deployen (bijvoorbeeld in een andere regio) is het dan een kwestie van het voorbereiden van de infrastructuur en het opnieuw pushen van de software. Houd er wel rekening mee dat dit geen herstelscenario voor data is.
Goede oplossingen gebruiken het Deployment Center voor Azure App Service of Azure DevOps om de Continuous improvement en Continuous Deployment te beheren. Als je op zoek bent naar een andere oplossing is GitHub ook een geweldige manier om te beginnen!
Wanneer je gebruik maakt van Virtual Machines, gebruik Azure Back-Up
Als je kiest voor een Single Instance Virtual Machine zonder SLA, zorg er dan voor dat je Azure Back-up implementeert zodat je een recovery scenario hebt. Bovendien kun je ook kijken naar Azure Recovery Service, waarbij je je omgeving over meerdere regio’s repliceert.
Wanneer je gebruik maakt van opslag (bijvoorbeeld Azure SQL, Storage accounts, CosmosDB), configureer Geo-replicatie
Wanneer je gebruik maakt van PaaS- resources activeer dan ook Geo Redundancy; dit is vaak een optie bij de configuratie. Door Geo Redundancy in te schakelen worden de gegevens gekopieerd naar andere regio’s (zorg er wel altijd voor dat wanneer het nodig is, het ook snel beschikbaar is).
Als je bijvoorbeeld gebruik maakt van een storage account geldt het volgende:
Geo-redundante opslag (GRS) is ontworpen om ten minste 99,99999999999% (16 9’s) duurzaamheid van objecten in een bepaald jaar te repliceren naar een secundaire regio met een grote afstand van de primaire regio. Als u storage-account GRS is ingeschakeld heeft, zijn uw gegevens duurzaam zelfs in geval van een volledige regionale stroomstoring of een ramp waarbij de primaire regio niet hersteld.
Bron: Microsoft, oktober 2018
Wanneer je gebruik maakt van Azure SQL of CosmosDB heb je veel meer opties tot je beschikking. Je kunt je applicatie configureren met actieve geo-replicatie waarmee je ook wereldwijde beschikbaarheid kunt garanderen (bekijk ons artikel over schalen).
Implementeer Traffic Manager
Traffic Manager is dé go-to-resource als jij je applicatie wereldwijd beschikbaar wil hebben.
Het is makkelijk te configureren, ondersteunt meerdere endpoints en integreert goed met Azure PaaS-resources. Traffic Manager biedt een centraal toegangspunt tot de applicatie en op basis van de gewenste route kan het verkeer naar de bijbehorende backend sturen. Dit is niet alleen handig bij het wereldwijd schalen van de oplossing (omdat traffic manager het verkeer kan leiden gebaseerd op de originele DNS aanvraag), maar het is ook een goede manier om ervoor te zorgen dat de klanten hun URL’s niet hoeven te wijzigingen wanneer er een regiofout optreedt.
![]()
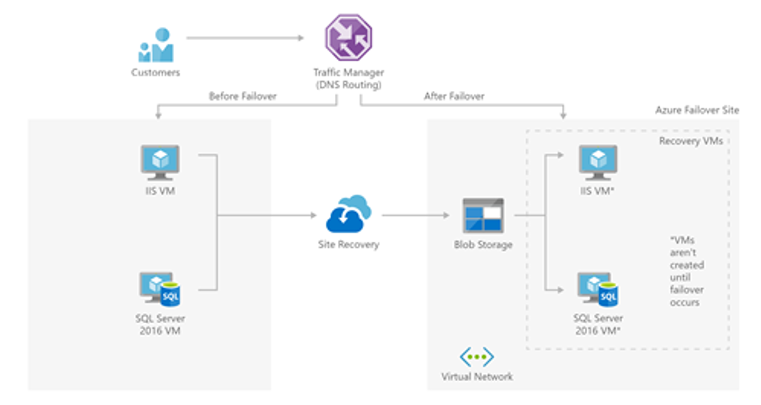
Bron: Microsoft
Microsoft heeft verschillende referentiearchitecturen met betrekking tot disaster recovery, deze kun je hier vinden. De komende periode publiceren wij van ieder onderdeel van de checklist meer informatie. Wil je dit niet missen? Laat je gegevens hier achter, dan houden we je op de hoogte.
